以下是 Tooltip风格工具栏 的示例演示效果:
部分效果截图1:
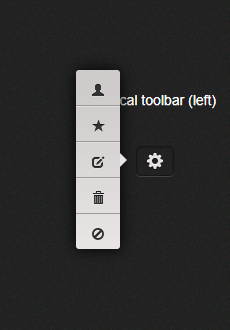
部分效果截图2:
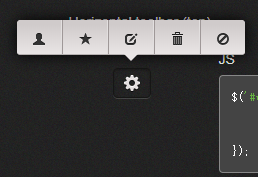
HTML代码(index.html):
<!DOCTYPE html>
<html>
<head>
<title>Tooltip�����</title>
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<link href="css/documentation.css" rel="stylesheet" />
<link href="css/jquery.toolbars.css" rel="stylesheet" />
<link href='http://fonts.googleapis.com/css?family=Lustria' rel='stylesheet' type='text/css'>
<!--[if gte IE 9]>
<style type="text/css">
.gradient {
filter: none !important;
}
.tool-container.tool-top {
border-bottom: none;
}
</style>
<![endif]-->
<link href="css/bootstrap.icons.css" rel="stylesheet">
<link href="css/prettify.css" rel="stylesheet">
<link href="css/sunburst.css" rel="stylesheet">
<script src="js/jquery-1.9.1.js"></script>
<script src="js/prettify.js"></script>
<script src="js/jquery.toolbar.js"></script>
<script type="text/javascript">
jQuery(document).ready(function($) {
// Define any icon actions before calling the toolbar
$('.toolbar-icons a').on('click', function( event ) {
event.preventDefault();
});
$('#normal-button').toolbar({content: '#user-options', position: 'top'});
$('#normal-button-bottom').toolbar({content: '#user-options', position: 'bottom'});
$('#normal-button-small').toolbar({content: '#user-options-small', position: 'top', hideOnClick: true});
$('#button-left').toolbar({content: '#user-options', position: 'left'});
$('#button-right').toolbar({content: '#user-options', position: 'right'});
$('#link-toolbar').toolbar({content: '#user-options', position: 'top'});
});
</script>
</head>
<body onload="prettyPrint()" >
<div class="tooltip-container normal">
<h2>Tooltip�����</h2>
<section>
<div class="example">
<p>Horizontal toolbar (top)</p>
<section class="left">
<div id="normal-button" class="settings-button"><img src="img/icon-cog-small.png" /></div>
</section>
<section class="right">
<span>JS</span>
<pre class="prettyprint">
$('#user-toolbar').toolbar({
content: '#user-toolbar-options',
position: 'top'
});</pre>
<span>HTML</span>
<pre class="prettyprint">
<div id="user-toolbar-options">
<a href="#"><i class="icon-user"></i></a>
<a href="#"><i class="icon-star"></i></a>
<a href="#"><i class="icon-edit"></i></a>
<a href="#"><i class="icon-delete"></i></a>
<a href="#"><i class="icon-ban"></i></a>
</div>
</pre>
</section>
<div class="clear"></div>
</div>
<div class="example">
<p>Horizontal toolbar (bottom)</p>
<section class="left">
<div id="normal-button-bottom" class="settings-button"><img src="img/icon-cog-small.png" /></div>
</section>
<section class="right">
<span>JS</span>
<pre class="prettyprint">
$('#user-toolbar').toolbar({
content: '#user-toolbar-options',
position: 'bottom'
});</pre>
<span>HTML</span>
<pre class="prettyprint">
<div id="user-toolbar-options">
<a href="#"><i class="icon-user"></i></a>
<a href="#"><i class="icon-star"></i></a>
<a href="#"><i class="icon-edit"></i></a>
<a href="#"><i class="icon-delete"></i></a>
<a href="#"><i class="icon-ban"></i></a>
</div>
</pre>
</section>
<div class="clear"></div>
</div>
<div class="example">
<p>Horizontal toolbar with three items</p>
<section class="left">
<div id="normal-button-small" class="settings-button"><img src="img/icon-cog-small.png" /></div>
</section>
<section class="right">
<span>JS</span>
<pre class="prettyprint">
$('#format-toolbar').toolbar({
content: '#format-toolbar-options',
position: 'top',
hideOnClick: true
});</pre>
<span>HTML</span>
<pre class="prettyprint">
<div id="format-toolbar-options">
<a href="#"><i class="icon-align-left"></i></a>
<a href="#"><i class="icon-align-center"></i></a>
<a href="#"><i class="icon-align-right"></i></a>
</div>
</pre>
</section>
<div class="clear"></div>
</div>
<div class="example">
<p>Vertical toolbar (left)</p>
<section class="left">
<a id="button-left" class="settings-button"><span></span></a>
</section>
<section class="right">
<span>JS</span>
<pre class="prettyprint">
$('#vertical-toolbar').toolbar({
content: '#user-toolbar-options',
position: 'left'
});</pre>
<span>HTML</span>
<pre class="prettyprint">
<div id="user-toolbar-options">
<a href="#"><i class="icon-user"></i></a>
<a href="#"><i class="icon-star"></i></a>
<a href="#"><i class="icon-edit"></i></a>
<a href="#"><i class="icon-delete"></i></a>
<a href="#"><i class="icon-ban"></i></a>
</div>
</pre>
</section>
<div class="clear"></div>
</div>
<div class="example">
<p>Vertical toolbar (right)</p>
<section class="left">
<a id="button-right" class="settings-button"><span></span></a>
</section>
<section class="right">
<span>JS</span>
<pre class="prettyprint">
$('#vertical-toolbar').toolbar({
content: '#user-toolbar-options',
position: 'right'
});</pre>
<span>HTML</span>
<pre class="prettyprint">
<div id="user-toolbar-options">
<a href="#"><i class="icon-user"></i></a>
<a href="#"><i class="icon-star"></i></a>
<a href="#"><i class="icon-edit"></i></a>
<a href="#"><i class="icon-delete"></i></a>
<a href="#"><i class="icon-ban"></i></a>
</div>
</pre>
</section>
<div class="clear"></div>
</div>
<div class="example">
<p>Horizontal toolbar triggered by a link</p>
<section class="left">
<a id="link-toolbar" class="demo-link">Options</a>
</section>
<section class="right">
<span>JS</span>
<pre class="prettyprint">
$('#normal-button').toolbar({
content: '#user-options',
position: 'top'
});</pre>
<span>HTML</span>
<pre class="prettyprint">
<div id="user-toolbar-options">
<a href="#"><i class="icon-user"></i></a>
<a href="#"><i class="icon-star"></i></a>
<a href="#"><i class="icon-edit"></i></a>
<a href="#"><i class="icon-delete"></i></a>
<a href="#"><i class="icon-ban"></i></a>
</div>
</pre>
</section>
<div class="clear"></div>
</div>
</section>
<section>
<h2>Usage</h2>
<span>Include the plugin javascript file along with jquery</span>
<pre class="prettyprint">
<script src="jquery.min.js"></script>
<script src="jquery.toolbar.js"></script>
</pre>
<br/>
<span>Include the css files</span>
<pre class="prettyprint">
<link href="jquery.toolbar.css" rel="stylesheet" />
<link href="bootstrap.icons.css" rel="stylesheet" />
</pre>
<br/>
<span>Define your toolbar HTML</span>
<pre class="prettyprint">
<div id="user-toolbar-options">
<a href="#"><i class="icon-user"></i></a>
<a href="#"><i class="icon-star"></i></a>
<a href="#"><i class="icon-edit"></i></a>
<a href="#"><i class="icon-delete"></i></a>
<a href="#"><i class="icon-ban"></i></a>
</div>
</pre>
<br/>
<span>Attach the toolbar to an element passing in your options as an object. Available options are detailed below.</span>
<pre class="prettyprint">
$('#element').toolbar( options );
</pre>
<br/>
<h3>Notes</h3>
<ul>
<li>The element that triggers the toolbar will gain the class <code>.pressed</code> when the toolbar is visible.</li>
<li>Define any javascript for icon actions before calling the toolbar.</li>
</ul>
</section>
<section>
<h2>Options</h2>
<table>
<thead>
<tr>
<th>Option</th>
<th>Description</th>
</tr>
</thead>
<tbody>
<tr>
<td>content</td>
<td>The id of the element containing the icons HTML.</td>
</tr>
<tr>
<td>position</td>
<td>Indicates the display position of the toobar relative to the element its attached agaisnt. Select either 'top', 'bottom', 'left' or 'right. Default: top.</td>
</tr>
<tr>
<td>hideOnClick</td>
<td>Choose if you want the toolbar to hide when anywhere outside the toolbar is clicked. Default: false.</td>
</tr>
</tbody>
</table>
<br/>
<h2>Methods</h2>
<p>Below is a list of methods available on the elements that already have a toolbar instantiated</p>
<table>
<thead>
<tr>
<th>Method</th>
<th>Arguments</th>
<th>Description</th>
</tr>
</thead>
<tbody>
<tr>
<td>getToolbarElement</td>
<td>None</td>
<td>Obtain the element that wraps every tool button</td>
</tr>
</tbody>
</table>
<br/>
<h2>Events</h2>
<p>Below are a list of events that are triggered when certain events happen with the toolbar. You can listen for these events using the .on method.</p>
<span>For example.</span>
<pre class="prettyprint">
$('#element').on('toolbarShown',
function( event ) {
// this: the element the toolbar is attached to
}
);
</pre>
<br/>
<table>
<thead>
<tr>
<th>Event</th>
<th>Description</th>
</tr>
</thead>
<tbody>
<tr>
<td>toolbarShown</td>
<td>Triggered when the toolbar is shown.</td>
</tr>
<tr>
<td>toolbarHidden</td>
<td>Triggered when the toolbar is hidden.</td>
</tr>
<tr>
<td>toolbarItemClick</td>
<td>Triggered when a button in the toolbar is clicked. The toolbar item clicked is also passed through for this event.</td>
</tr>
</tbody>
</table>
</section>
<footer>
</footer>
</div>
<div id="user-options-small" class="toolbar-icons" style="display: none;">
<a href=""><i class="icon-align-left"></i></a>
<a href=""><i class="icon-align-center"></i></a>
<a href=""><i class="icon-align-right"></i></a>
</div>
<div id="user-options" class="toolbar-icons" style="display: none;">
<a href="#"><i class="icon-user"></i></a>
<a href="#"><i class="icon-star"></i></a>
<a href="#"><i class="icon-edit"></i></a>
<a href="#"><i class="icon-trash"></i></a>
<a href="#"><i class="icon-ban-circle"></i></a>
</div>
</body>
</html>JS代码(prettify.js):
// Copyright (C) 2006 Google Inc.//// Licensed under the Apache License,Version 2.0 (the "License");
// you may not use this file except in compliance with the License.// You may obtain a copy of the License at//// http://www.apache.org/licenses/LICENSE-2.0//// Unless required by applicable law or agreed to in writing,software// distributed under the License is distributed on an "AS IS" BASIS,// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND,either express or implied.// See the License for the specific language governing permissions and// limitations under the License./** * @fileoverview * some functions for browser-side pretty printing of code contained in html. * * <p> * For a fairly comprehensive set of languages see the * <a href="http://google-code-prettify.googlecode.com/svn/trunk/README.html#langs">README</a> * file that came with this source. At a minimum,the lexer should work on a * number of languages including C and friends,Java,Python,Bash,SQL,HTML,* XML,CSS,Javascript,and Makefiles. It works passably on Ruby,PHP and Awk * and a subset of Perl,but,because of commenting conventions,doesn't work on * Smalltalk,Lisp-like,or CAML-like languages without an explicit lang class. * <p> * Usage:<ol> * <li> include this source file in an html page via *{
@code <script type="text/javascript" src="/path/to/prettify.js"></script>}
* <li> define style rules. See the example page for examples. * <li> mark the{
@code <pre>}
and{
@code <code>}
tags in your source with *{
@code class=prettyprint.}
* You can also use the (html deprecated){
@code <xmp>}
tag,but the pretty * printer needs to do more substantial DOM manipulations to support that,so * some css styles may not be preserved. * </ol> * That's it. I wanted to keep the API as simple as possible,so there's no * need to specify which language the code is in,but if you wish,you can add * another class to the{
@code <pre>}
or{
@code <code>}
element to specify the * language,as in{
@code <pre class="prettyprint lang-java">}
. Any class that * starts with "lang-" followed by a file extension,specifies the file type. * See the "lang-*.js" files in this directory for code that implements * per-language file handlers. * <p> * Change log:<br> * cbeust,2006/08/22 * <blockquote> * Java annotations (start with "@") are now captured as literals ("lit") * </blockquote> * @requires console */
// JSLint declarations/*global console,document,navigator,setTimeout,window */
/** * Split{
@code prettyPrint}
into multiple timeouts so as not to interfere with * UI events. * If set to{
@code false}
,{
@code prettyPrint()}
is synchronous. */
window['PR_SHOULD_USE_CONTINUATION'] = true;
(function (){
// Keyword lists for various languages. // We use things that coerce to strings to make them compact when minified // and to defeat aggressive optimizers that fold large string constants. var FLOW_CONTROL_KEYWORDS = ["break,continue,do,else,for,if,return,while"];
var C_KEYWORDS = [FLOW_CONTROL_KEYWORDS,"auto,case,char,const,default," + "double,enum,extern,float,goto,int,long,register,short,signed,sizeof," + "static,struct,switch,typedef,union,unsigned,void,volatile"];
var COMMON_KEYWORDS = [C_KEYWORDS,"catch,class,delete,false,import," + "new,operator,private,protected,public,this,throw,true,try,typeof"];
var CPP_KEYWORDS = [COMMON_KEYWORDS,"alignof,align_union,asm,axiom,bool," + "concept,concept_map,const_cast,constexpr,decltype," + "dynamic_cast,explicit,export,friend,inline,late_check," + "mutable,namespace,nullptr,reinterpret_cast,static_assert,static_cast," + "template,typeid,typename,using,virtual,where"];
var JAVA_KEYWORDS = [COMMON_KEYWORDS,"abstract,boolean,byte,extends,final,finally,implements,import," + "instanceof,null,native,package,strictfp,super,synchronized,throws," + "transient"];
var CSHARP_KEYWORDS = [JAVA_KEYWORDS,"as,base,by,checked,decimal,delegate,descending,dynamic,event," + "fixed,foreach,from,group,implicit,in,interface,internal,into,is,lock," + "object,out,override,orderby,params,partial,readonly,ref,sbyte,sealed," + "stackalloc,string,select,uint,ulong,unchecked,unsafe,ushort,var"];
var COFFEE_KEYWORDS = "all,and,by,catch,class,else,extends,false,finally," + "for,if,in,is,isnt,loop,new,no,not,null,of,off,on,or,return,super,then," + "true,try,unless,until,when,while,yes";
var JSCRIPT_KEYWORDS = [COMMON_KEYWORDS,"debugger,eval,export,function,get,null,set,undefined,var,with," + "Infinity,NaN"];
var PERL_KEYWORDS = "caller,delete,die,do,dump,elsif,eval,exit,foreach,for," + "goto,if,import,last,local,my,next,no,our,print,package,redo,require," + "sub,undef,unless,until,use,wantarray,while,BEGIN,END";
var PYTHON_KEYWORDS = [FLOW_CONTROL_KEYWORDS,"and,as,assert,class,def,del," + "elif,except,exec,finally,from,global,import,in,is,lambda," + "nonlocal,not,or,pass,print,raise,try,with,yield," + "False,True,None"];
var RUBY_KEYWORDS = [FLOW_CONTROL_KEYWORDS,"alias,and,begin,case,class," + "def,defined,elsif,end,ensure,false,in,module,next,nil,not,or,redo," + "rescue,retry,self,super,then,true,undef,unless,until,when,yield," + "BEGIN,END"];
var SH_KEYWORDS = [FLOW_CONTROL_KEYWORDS,"case,done,elif,esac,eval,fi," + "function,in,local,set,then,until"];
var ALL_KEYWORDS = [ CPP_KEYWORDS,CSHARP_KEYWORDS,JSCRIPT_KEYWORDS,PERL_KEYWORDS + PYTHON_KEYWORDS,RUBY_KEYWORDS,SH_KEYWORDS];
var C_TYPES = /^(DIR|FILE|vector|(de|priority_)?queue|list|stack|(const_)?iterator|(multi)?(set|map)|bitset|u?(int|float)\d*)/;
// token style names. correspond to css classes /** * token style for a string literal * @const */
var PR_STRING = 'str';
/** * token style for a keyword * @const */
var PR_KEYWORD = 'kwd';
/** * token style for a comment * @const */
var PR_COMMENT = 'com';
/** * token style for a type * @const */
var PR_TYPE = 'typ';
/** * token style for a literal value. e.g. 1,null,true. * @const */
var PR_LITERAL = 'lit';
/** * token style for a punctuation string. * @const */
var PR_PUNCTUATION = 'pun';
/** * token style for a punctuation string. * @const */
var PR_PLAIN = 'pln';
/** * token style for an sgml tag. * @const */
var PR_TAG = 'tag';
/** * token style for a markup declaration such as a DOCTYPE. * @const */
var PR_DECLARATION = 'dec';
/** * token style for embedded source. * @const */
var PR_SOURCE = 'src';
/** * token style for an sgml attribute name. * @const */
var PR_ATTRIB_NAME = 'atn';
/** * token style for an sgml attribute value. * @const */
var PR_ATTRIB_VALUE = 'atv';
/** * A class that indicates a section of markup that is not code,e.g. to allow * embedding of line numbers within code listings. * @const */
var PR_NOCODE = 'nocode';
/** * A set of tokens that can precede a regular expression literal in * javascript * http://web.archive.org/web/20070717142515/http://www.mozilla.org/js/language/js20/rationale/syntax.html * has the full list,but I've removed ones that might be problematic when * seen in languages that don't support regular expression literals. * * <p>Specifically,I've removed any keywords that can't precede a regexp * literal in a syntactically legal javascript program,and I've removed the * "in" keyword since it's not a keyword in many languages,and might be used * as a count of inches. * * <p>The link a above does not accurately describe EcmaScript rules since * it fails to distinguish between (a=++/b/i) and (a++/b/i) but it works * very well in practice. * * @private * @const */
var REGEXP_PRECEDER_PATTERN = '(?:^^\\.?|[+-]|\\!|\\!=|\\!==|\\#|\\%|\\%=|&|&&|&&=|&=|\\(|\\*|\\*=|\\+=|\\,|\\-=|\\->|\\/|\\/=|:|::|\\;
|<|<<|<<=|<=|=|==|===|>|>=|>>|>>=|>>>|>>>=|\\?|\\@|\\[|\\^|\\^=|\\^\\^|\\^\\^=|\\{
|\\||\\|=|\\|\\||\\|\\|=|\\~|break|case|continue|delete|do|else|finally|instanceof|return|throw|try|typeof)\\s*';
// CAVEAT:this does not properly handle the case where a regular// expression immediately follows another since a regular expression may// have flags for case-sensitivity and the like. Having regexp tokens// adjacent is not valid in any language I'm aware of,so I'm punting.// TODO:maybe style special characters inside a regexp as punctuation. /** * Given a group of{
@link RegExp}
s,returns a{
@code RegExp}
that globally * matches the union of the sets of strings matched by the input RegExp. * Since it matches globally,if the input strings have a start-of-input * anchor (/^.../),it is ignored for the purposes of unioning. * @param{
Array.<RegExp>}
regexs non multiline,non-global regexs. * @return{
RegExp}
a global regex. */
function combinePrefixPatterns(regexs){
var capturedGroupIndex = 0;
var needToFoldCase = false;
var ignoreCase = false;
for (var i = 0,n = regexs.length;
i < n;
++i){
var regex = regexs[i];
if (regex.ignoreCase){
ignoreCase = true;
}
else if (/[a-z]/i.test(regex.source.replace( /\\u[0-9a-f]{
4}
|\\x[0-9a-f]{
2}
|\\[^ux]/gi,''))){
needToFoldCase = true;
ignoreCase = false;
break;
}
}
var escapeCharToCodeUnit ={
'b':8,'t':9,'n':0xa,'v':0xb,'f':0xc,'r':0xd}
;
function decodeEscape(charsetPart){
var cc0 = charsetPart.charCodeAt(0);
if (cc0 !== 92 /* \\ */
){
return cc0;
}
var c1 = charsetPart.charAt(1);
cc0 = escapeCharToCodeUnit[c1];
if (cc0){
return cc0;
}
else if ('0' <= c1 && c1 <= '7'){
return parseInt(charsetPart.substring(1),8);
}
else if (c1 === 'u' || c1 === 'x'){
return parseInt(charsetPart.substring(2),16);
}
else{
return charsetPart.charCodeAt(1);
}
}
function encodeEscape(charCode){
if (charCode < 0x20){
return (charCode < 0x10 ? '\\x0':'\\x') + charCode.toString(16);
}
var ch = String.fromCharCode(charCode);
if (ch === '\\' || ch === '-' || ch === '[' || ch === ']'){
ch = '\\' + ch;
}
return ch;
}
function caseFoldCharset(charSet){
var charsetParts = charSet.substring(1,charSet.length - 1).match( new RegExp( '\\\\u[0-9A-Fa-f]{
4}
' + '|\\\\x[0-9A-Fa-f]{
2}
' + '|\\\\[0-3][0-7]{
0,2}
' + '|\\\\[0-7]{
1,2}
' + '|\\\\[\\s\\S]' + '|-' + '|[^-\\\\]','g'));
var groups = [];
var ranges = [];
var inverse = charsetParts[0] === '^';
for (var i = inverse ? 1:0,n = charsetParts.length;
i < n;
++i){
var p = charsetParts[i];
if (/\\[bdsw]/i.test(p)){
// Don't muck with named groups. groups.push(p);
}
else{
var start = decodeEscape(p);
var end;
if (i + 2 < n && '-' === charsetParts[i + 1]){
end = decodeEscape(charsetParts[i + 2]);
i += 2;
}
else{
end = start;
}
ranges.push([start,end]);
// If the range might intersect letters,then expand it. // This case handling is too simplistic. // It does not deal with non-latin case folding. // It works for latin source code identifiers though. if (!(end < 65 || start > 122)){
if (!(end < 65 || start > 90)){
ranges.push([Math.max(65,start) | 32,Math.min(end,90) | 32]);
}
if (!(end < 97 || start > 122)){
ranges.push([Math.max(97,start) & ~32,Math.min(end,122) & ~32]);
}
}
}
}
// [[1,10],[3,4],[8,12],[14,14],[16,16],[17,17]] // -> [[1,12],[14,14],[16,17]] ranges.sort(function (a,b){
return (a[0] - b[0]) || (b[1] - a[1]);
}
);
var consolidatedRanges = [];
var lastRange = [NaN,NaN];
for (var i = 0;
i < ranges.length;
++i){
var range = ranges[i];
if (range[0] <= lastRange[1] + 1){
lastRange[1] = Math.max(lastRange[1],range[1]);
}
else{
consolidatedRanges.push(lastRange = range);
}
}
var out = ['['];
if (inverse){
out.push('^');
}
out.push.apply(out,groups);
for (var i = 0;
i < consolidatedRanges.length;
++i){
var range = consolidatedRanges[i];
out.push(encodeEscape(range[0]));
if (range[1] > range[0]){
if (range[1] + 1 > range[0]){
out.push('-');
}
out.push(encodeEscape(range[1]));
}
}
out.push(']');
return out.join('');
}
function allowAnywhereFoldCaseAndRenumberGroups(regex){
// Split into character sets,escape sequences,punctuation strings // like ('(','(?:',')','^'),and runs of characters that do not // include any of the above. var parts = regex.source.match( new RegExp( '(?:' + '\\[(?:[^\\x5C\\x5D]|\\\\[\\s\\S])*\\]' // a character set + '|\\\\u[A-Fa-f0-9]{
4}
' // a unicode escape + '|\\\\x[A-Fa-f0-9]{
2}
' // a hex escape + '|\\\\[0-9]+' // a back-reference or octal escape + '|\\\\[^ux0-9]' // other escape sequence + '|\\(\\?[:!=]' // start of a non-capturing group + '|[\\(\\)\\^]' // start/emd of a group,or line start + '|[^\\x5B\\x5C\\(\\)\\^]+' // run of other characters + ')','g'));
var n = parts.length;
// Maps captured group numbers to the number they will occupy in // the output or to -1 if that has not been determined,or to // undefined if they need not be capturing in the output. var capturedGroups = [];
// Walk over and identify back references to build the capturedGroups // mapping. for (var i = 0,groupIndex = 0;
i < n;
++i){
var p = parts[i];
if (p === '('){
// groups are 1-indexed,so max group index is count of '(' ++groupIndex;
}
else if ('\\' === p.charAt(0)){
var decimalValue = +p.substring(1);
if (decimalValue && decimalValue <= groupIndex){
capturedGroups[decimalValue] = -1;
}
}
}
// Renumber groups and reduce capturing groups to non-capturing groups // where possible. for (var i = 1;
i < capturedGroups.length;
++i){
if (-1 === capturedGroups[i]){
capturedGroups[i] = ++capturedGroupIndex;
}
}
for (var i = 0,groupIndex = 0;
i < n;
++i){
var p = parts[i];
if (p === '('){
++groupIndex;
if (capturedGroups[groupIndex] === undefined){
parts[i] = '(?:';
}
}
else if ('\\' === p.charAt(0)){
var decimalValue = +p.substring(1);
if (decimalValue && decimalValue <= groupIndex){
parts[i] = '\\' + capturedGroups[groupIndex];
}
}
}
// Remove any prefix anchors so that the output will match anywhere. // ^^ really does mean an anchored match though. for (var i = 0,groupIndex = 0;
i < n;
++i){
if ('^' === parts[i] && '^' !== parts[i + 1]){
parts[i] = '';
}
}
// Expand letters to groups to handle mixing of case-sensitive and // case-insensitive patterns if necessary. if (regex.ignoreCase && needToFoldCase){
for (var i = 0;
i < n;
++i){
var p = parts[i];
var ch0 = p.charAt(0);
if (p.length >= 2 && ch0 === '['){
parts[i] = caseFoldCharset(p);
}
else if (ch0 !== '\\'){
// TODO:handle letters in numeric escapes. parts[i] = p.replace( /[a-zA-Z]/g,function (ch){
var cc = ch.charCodeAt(0);
return '[' + String.fromCharCode(cc & ~32,cc | 32) + ']';
}
);
}
}
}
return parts.join('');
}
var rewritten = [];
for (var i = 0,n = regexs.length;
i < n;
++i){
var regex = regexs[i];
if (regex.global || regex.multiline){
throw new Error('' + regex);
}
rewritten.push( '(?:' + allowAnywhereFoldCaseAndRenumberGroups(regex) + ')');
}
return new RegExp(rewritten.join('|'),ignoreCase ? 'gi':'g');
}
/** * Split markup into a string of source code and an array mapping ranges in * that string to the text nodes in which they appear. * * <p> * The HTML DOM structure:</p> * <pre> * (Element "p" * (Element "b" * (Text "print "));
#1 * (Text "'Hello '");
#2 * (Element "br");
#3 * (Text " + 'World';
"));
#4 * </pre> * <p> * corresponds to the HTML *{
@code <p><b>print </b>'Hello '<br> + 'World';
</p>}
.</p> * * <p> * It will produce the output:</p> * <pre> *{
* sourceCode:"print 'Hello '\n + 'World';
",* // 1 2 * // 012345678901234 5678901234567 * spans:[0,#1,6,#2,14,#3,15,#4] *}
* </pre> * <p> * where #1 is a reference to the{
@code "print "}
text node above,and so * on for the other text nodes. * </p> * * <p> * The{
@code}
spans array is an array of pairs. Even elements are the start * indices of substrings,and odd elements are the text nodes (or BR elements) * that contain the text for those substrings. * Substrings continue until the next index or the end of the source. * </p> * * @param{
Node}
node an HTML DOM subtree containing source-code. * @return{
Object}
source code and the text nodes in which they occur. */
function extractSourceSpans(node){
var nocode = /(?:^|\s)nocode(?:\s|$)/;
var chunks = [];
var length = 0;
var spans = [];
var k = 0;
var whitespace;
if (node.currentStyle){
whitespace = node.currentStyle.whiteSpace;
}
else if (window.getComputedStyle){
whitespace = document.defaultView.getComputedStyle(node,null) .getPropertyValue('white-space');
}
var isPreformatted = whitespace && 'pre' === whitespace.substring(0,3);
function walk(node){
switch (node.nodeType){
case 1:// Element if (nocode.test(node.className)){
return;
}
for (var child = node.firstChild;
child;
child = child.nextSibling){
walk(child);
}
var nodeName = node.nodeName;
if ('BR' === nodeName || 'LI' === nodeName){
chunks[k] = '\n';
spans[k << 1] = length++;
spans[(k++ << 1) | 1] = node;
}
break;
case 3:case 4:// Text var text = node.nodeValue;
if (text.length){
if (!isPreformatted){
text = text.replace(/[ \t\r\n]+/g,' ');
}
else{
text = text.replace(/\r\n?/g,'\n');
// Normalize newlines.}
// TODO:handle tabs here? chunks[k] = text;
spans[k << 1] = length;
length += text.length;
spans[(k++ << 1) | 1] = node;
}
break;
}
}
walk(node);
return{
sourceCode:chunks.join('').replace(/\n$/,''),spans:spans}
;
}
/** * Apply the given language handler to sourceCode and add the resulting * decorations to out. * @param{
number}
basePos the index of sourceCode within the chunk of source * whose decorations are already present on out. */
function appendDecorations(basePos,sourceCode,langHandler,out){
if (!sourceCode){
return;
}
var job ={
sourceCode:sourceCode,basePos:basePos}
;
langHandler(job);
out.push.apply(out,job.decorations);
}
var notWs = /\S/;
/** * Given an element,if it contains only one child element and any text nodes * it contains contain only space characters,return the sole child element. * Otherwise returns undefined. * <p> * This is meant to return the CODE element in{
@code <pre><code ...>}
when * there is a single child element that contains all the non-space textual * content,but not to return anything where there are multiple child elements * as in{
@code <pre><code>...</code><code>...</code></pre>}
or when there * is textual content. */
function childContentWrapper(element){
var wrapper = undefined;
for (var c = element.firstChild;
c;
c = c.nextSibling){
var type = c.nodeType;
wrapper = (type === 1) // Element Node ? (wrapper ? element:c):(type === 3) // Text Node ? (notWs.test(c.nodeValue) ? element:wrapper):wrapper;
}
return wrapper === element ? undefined:wrapper;
}
/** Given triples of [style,pattern,context] returns a lexing function,* The lexing function interprets the patterns to find token boundaries and * returns a decoration list of the form * [index_0,style_0,index_1,style_1,...,index_n,style_n] * where index_n is an index into the sourceCode,and style_n is a style * constant like PR_PLAIN. index_n-1 <= index_n,and style_n-1 applies to * all characters in sourceCode[index_n-1:index_n]. * * The stylePatterns is a list whose elements have the form * [style:string,pattern:RegExp,DEPRECATED,shortcut:string]. * * Style is a style constant like PR_PLAIN,or can be a string of the * form 'lang-FOO',where FOO is a language extension describing the * language of the portion of the token in $1 after pattern executes. * E.g.,if style is 'lang-lisp',and group 1 contains the text * '(hello (world))',then that portion of the token will be passed to the * registered lisp handler for formatting. * The text before and after group 1 will be restyled using this decorator * so decorators should take care that this doesn't result in infinite * recursion. For example,the HTML lexer rule for SCRIPT elements looks * something like ['lang-js',/<[s]cript>(.+?)<\/script>/]. This may match * '<script>foo()<\/script>',which would cause the current decorator to * be called with '<script>' which would not match the same rule since * group 1 must not be empty,so it would be instead styled as PR_TAG by * the generic tag rule. The handler registered for the 'js' extension would * then be called with 'foo()',and finally,the current decorator would * be called with '<\/script>' which would not match the original rule and * so the generic tag rule would identify it as a tag. * * Pattern must only match prefixes,and if it matches a prefix,then that * match is considered a token with the same style. * * Context is applied to the last non-whitespace,non-comment token * recognized. * * Shortcut is an optional string of characters,any of which,if the first * character,gurantee that this pattern and only this pattern matches. * * @param{
Array}
shortcutStylePatterns patterns that always start with * a known character. Must have a shortcut string. * @param{
Array}
fallthroughStylePatterns patterns that will be tried in * order if the shortcut ones fail. May have shortcuts. * * @return{
function (Object)}
a * function that takes source code and returns a list of decorations. */
function createSimpleLexer(shortcutStylePatterns,fallthroughStylePatterns){
var shortcuts ={
}
;
var tokenizer;
(function (){
var allPatterns = shortcutStylePatterns.concat(fallthroughStylePatterns);
var allRegexs = [];
var regexKeys ={
}
;
for (var i = 0,n = allPatterns.length;
i < n;
++i){
var patternParts = allPatterns[i];
var shortcutChars = patternParts[3];
if (shortcutChars){
for (var c = shortcutChars.length;
--c >= 0;
){
shortcuts[shortcutChars.charAt(c)] = patternParts;
}
}
var regex = patternParts[1];
var k = '' + regex;
if (!regexKeys.hasOwnProperty(k)){
allRegexs.push(regex);
regexKeys[k] = null;
}
}
allRegexs.push(/[\0-\uffff]/);
tokenizer = combinePrefixPatterns(allRegexs);
}
)();
var nPatterns = fallthroughStylePatterns.length;
/** * Lexes job.sourceCode and produces an output array job.decorations of * style classes preceded by the position at which they start in * job.sourceCode in order. * * @param{
Object}
job an object like <pre>{
* sourceCode:{
string}
sourceText plain text,* basePos:{
int}
position of job.sourceCode in the larger chunk of * sourceCode. *}
</pre> */
var decorate = function (job){
var sourceCode = job.sourceCode,basePos = job.basePos;
/** Even entries are positions in source in ascending order. Odd enties * are style markers (e.g.,PR_COMMENT) that run from that position until * the end. * @type{
Array.<number|string>}
*/
var decorations = [basePos,PR_PLAIN];
var pos = 0;
// index into sourceCode var tokens = sourceCode.match(tokenizer) || [];
var styleCache ={
}
;
for (var ti = 0,nTokens = tokens.length;
ti < nTokens;
++ti){
var token = tokens[ti];
var style = styleCache[token];
var match = void 0;
var isEmbedded;
if (typeof style === 'string'){
isEmbedded = false;
}
else{
var patternParts = shortcuts[token.charAt(0)];
if (patternParts){
match = token.match(patternParts[1]);
style = patternParts[0];
}
else{
for (var i = 0;
i < nPatterns;
++i){
patternParts = fallthroughStylePatterns[i];
match = token.match(patternParts[1]);
if (match){
style = patternParts[0];
break;
}
}
if (!match){
// make sure that we make progress style = PR_PLAIN;
}
}
isEmbedded = style.length >= 5 && 'lang-' === style.substring(0,5);
if (isEmbedded && !(match && typeof match[1] === 'string')){
isEmbedded = false;
style = PR_SOURCE;
}
if (!isEmbedded){
styleCache[token] = style;
}
}
var tokenStart = pos;
pos += token.length;
if (!isEmbedded){
decorations.push(basePos + tokenStart,style);
}
else{
// Treat group 1 as an embedded block of source code. var embeddedSource = match[1];
var embeddedSourceStart = token.indexOf(embeddedSource);
var embeddedSourceEnd = embeddedSourceStart + embeddedSource.length;
if (match[2]){
// If embeddedSource can be blank,then it would match at the // beginning which would cause us to infinitely recurse on the // entire token,so we catch the right context in match[2]. embeddedSourceEnd = token.length - match[2].length;
embeddedSourceStart = embeddedSourceEnd - embeddedSource.length;
}
var lang = style.substring(5);
// Decorate the left of the embedded source appendDecorations( basePos + tokenStart,token.substring(0,embeddedSourceStart),decorate,decorations);
// Decorate the embedded source appendDecorations( basePos + tokenStart + embeddedSourceStart,embeddedSource,langHandlerForExtension(lang,embeddedSource),decorations);
// Decorate the right of the embedded section appendDecorations( basePos + tokenStart + embeddedSourceEnd,token.substring(embeddedSourceEnd),decorate,decorations);
}
}
job.decorations = decorations;
}
;
return decorate;
}
/** returns a function that produces a list of decorations from source text. * * This code treats ",',and ` as string delimiters,and \ as a string * escape. It does not recognize perl's qq() style strings. * It has no special handling for double delimiter escapes as in basic,or * the tripled delimiters used in python,but should work on those regardless * although in those cases a single string literal may be broken up into * multiple adjacent string literals. * * It recognizes C,C++,and shell style comments. * * @param{
Object}
options a set of optional parameters. * @return{
function (Object)}
a function that examines the source code * in the input job and builds the decoration list. */
function sourceDecorator(options){
var shortcutStylePatterns = [],fallthroughStylePatterns = [];
if (options['tripleQuotedStrings']){
// '''multi-line-string''','single-line-string',and double-quoted shortcutStylePatterns.push( [PR_STRING,/^(?:\'\'\'(?:[^\'\\]|\\[\s\S]|\'{
1,2}
(?=[^\']))*(?:\'\'\'|$)|\"\"\"(?:[^\"\\]|\\[\s\S]|\"{
1,2}
(?=[^\"]))*(?:\"\"\"|$)|\'(?:[^\\\']|\\[\s\S])*(?:\'|$)|\"(?:[^\\\"]|\\[\s\S])*(?:\"|$))/,null,'\'"']);
}
else if (options['multiLineStrings']){
// 'multi-line-string',"multi-line-string" shortcutStylePatterns.push( [PR_STRING,/^(?:\'(?:[^\\\']|\\[\s\S])*(?:\'|$)|\"(?:[^\\\"]|\\[\s\S])*(?:\"|$)|\`(?:[^\\\`]|\\[\s\S])*(?:\`|$))/,null,'\'"`']);
}
else{
// 'single-line-string',"single-line-string" shortcutStylePatterns.push( [PR_STRING,/^(?:\'(?:[^\\\'\r\n]|\\.)*(?:\'|$)|\"(?:[^\\\"\r\n]|\\.)*(?:\"|$))/,null,'"\'']);
}
if (options['verbatimStrings']){
// verbatim-string-literal production from the C# grammar. See issue 93. fallthroughStylePatterns.push( [PR_STRING,/^@\"(?:[^\"]|\"\")*(?:\"|$)/,null]);
}
var hc = options['hashComments'];
if (hc){
if (options['cStyleComments']){
if (hc > 1){
// multiline hash comments shortcutStylePatterns.push( [PR_COMMENT,/^#(?:##(?:[^#]|#(?!##))*(?:###|$)|.*)/,null,'#']);
}
else{
// Stop C preprocessor declarations at an unclosed open comment shortcutStylePatterns.push( [PR_COMMENT,/^#(?:(?:define|elif|else|endif|error|ifdef|include|ifndef|line|pragma|undef|warning)\b|[^\r\n]*)/,null,'#']);
}
fallthroughStylePatterns.push( [PR_STRING,/^<(?:(?:(?:\.\.\/)*|\/?)(?:[\w-]+(?:\/[\w-]+)+)?[\w-]+\.h|[a-z]\w*)>/,null]);
}
else{
shortcutStylePatterns.push([PR_COMMENT,/^#[^\r\n]*/
,null,'#']);
}
}
if (options['cStyleComments']){
fallthroughStylePatterns.push([PR_COMMENT,/^\/\/[^\r\n]*/
,null]);
fallthroughStylePatterns.push( [PR_COMMENT,/^\/\*[\s\S]*?(?:\*\/|$)/,null]);
}
if (options['regexLiterals']){
/** * @const */
var REGEX_LITERAL = ( // A regular expression literal starts with a slash that is // not followed by * or / so that it is not confused with // comments. '/(?=[^/*])' // and then contains any number of raw characters,+ '(?:[^/\\x5B\\x5C]' // escape sequences (\x5C),+ '|\\x5C[\\s\\S]' // or non-nesting character sets (\x5B\x5D);
+ '|\\x5B(?:[^\\x5C\\x5D]|\\x5C[\\s\\S])*(?:\\x5D|$))+' // finally closed by a /. + '/');
fallthroughStylePatterns.push( ['lang-regex',new RegExp('^' + REGEXP_PRECEDER_PATTERN + '(' + REGEX_LITERAL + ')') ]);
}
var types = options['types'];
if (types){
fallthroughStylePatterns.push([PR_TYPE,types]);
}
var keywords = ("" + options['keywords']).replace(/^ | $/g,'');
if (keywords.length){
fallthroughStylePatterns.push( [PR_KEYWORD,new RegExp('^(?:' + keywords.replace(/[\s,]+/g,'|') + ')\\b'),null]);
}
shortcutStylePatterns.push([PR_PLAIN,/^\s+/,null,' \r\n\t\xA0']);
fallthroughStylePatterns.push( // TODO(mikesamuel):recognize non-latin letters and numerals in idents [PR_LITERAL,/^@[a-z_$][a-z_$@0-9]*/
i,null],[PR_TYPE,/^(?:[@_]?[A-Z]+[a-z][A-Za-z_$@0-9]*|\w+_t\b)/,null],[PR_PLAIN,/^[a-z_$][a-z_$@0-9]*/
i,null],[PR_LITERAL,new RegExp( '^(?:' // A hex number + '0x[a-f0-9]+' // or an octal or decimal number,+ '|(?:\\d(?:_\\d+)*\\d*(?:\\.\\d*)?|\\.\\d\\+)' // possibly in scientific notation + '(?:e[+\\-]?\\d+)?' + ')' // with an optional modifier like UL for unsigned long + '[a-z]*','i'),null,'0123456789'],// Don't treat escaped quotes in bash as starting strings. See issue 144. [PR_PLAIN,/^\\[\s\S]?/,null],[PR_PUNCTUATION,/^.[^\s\w\.$@\'\"\`\/\#\\]*/
,null]);
return createSimpleLexer(shortcutStylePatterns,fallthroughStylePatterns);
}
var decorateSource = sourceDecorator({
'keywords':ALL_KEYWORDS,'hashComments':true,'cStyleComments':true,'multiLineStrings':true,'regexLiterals':true}
);
/** * Given a DOM subtree,wraps it in a list,and puts each line into its own * list item. * * @param{
Node}
node modified in place. Its content is pulled into an * HTMLOListElement,and each line is moved into a separate list item. * This requires cloning elements,so the input might not have unique * IDs after numbering. */
function numberLines(node,opt_startLineNum){
var nocode = /(?:^|\s)nocode(?:\s|$)/;
var lineBreak = /\r\n?|\n/;
var document = node.ownerDocument;
var whitespace;
if (node.currentStyle){
whitespace = node.currentStyle.whiteSpace;
}
else if (window.getComputedStyle){
whitespace = document.defaultView.getComputedStyle(node,null) .getPropertyValue('white-space');
}
// If it's preformatted,then we need to split lines on line breaks // in addition to <BR>s. var isPreformatted = whitespace && 'pre' === whitespace.substring(0,3);
var li = document.createElement('LI');
while (node.firstChild){
li.appendChild(node.firstChild);
}
// An array of lines. We split below,so this is initialized to one // un-split line. var listItems = [li];
function walk(node){
switch (node.nodeType){
case 1:// Element if (nocode.test(node.className)){
break;
}
if ('BR' === node.nodeName){
breakAfter(node);
// Discard the <BR> since it is now flush against a </LI>. if (node.parentNode){
node.parentNode.removeChild(node);
}
}
else{
for (var child = node.firstChild;
child;
child = child.nextSibling){
walk(child);
}
}
break;
case 3:case 4:// Text if (isPreformatted){
var text = node.nodeValue;
var match = text.match(lineBreak);
if (match){
var firstLine = text.substring(0,match.index);
node.nodeValue = firstLine;
var tail = text.substring(match.index + match[0].length);
if (tail){
var parent = node.parentNode;
parent.insertBefore( document.createTextNode(tail),node.nextSibling);
}
breakAfter(node);
if (!firstLine){
// Don't leave blank text nodes in the DOM. node.parentNode.removeChild(node);
}
}
}
break;
}
}
// Split a line after the given node. function breakAfter(lineEndNode){
// If there's nothing to the right,then we can skip ending the line // here,and move root-wards since splitting just before an end-tag // would require us to create a bunch of empty copies. while (!lineEndNode.nextSibling){
lineEndNode = lineEndNode.parentNode;
if (!lineEndNode){
return;
}
}
function breakLeftOf(limit,copy){
// Clone shallowly if this node needs to be on both sides of the break. var rightSide = copy ? limit.cloneNode(false):limit;
var parent = limit.parentNode;
if (parent){
// We clone the parent chain. // This helps us resurrect important styling elements that cross lines. // E.g. in <i>Foo<br>Bar</i> // should be rewritten to <li><i>Foo</i></li><li><i>Bar</i></li>. var parentClone = breakLeftOf(parent,1);
// Move the clone and everything to the right of the original // onto the cloned parent. var next = limit.nextSibling;
parentClone.appendChild(rightSide);
for (var sibling = next;
sibling;
sibling = next){
next = sibling.nextSibling;
parentClone.appendChild(sibling);
}
}
return rightSide;
}
var copiedListItem = breakLeftOf(lineEndNode.nextSibling,0);
// Walk the parent chain until we reach an unattached LI. for (var parent;
// Check nodeType since IE invents document fragments. (parent = copiedListItem.parentNode) && parent.nodeType === 1;
){
copiedListItem = parent;
}
// Put it on the list of lines for later processing. listItems.push(copiedListItem);
}
// Split lines while there are lines left to split. for (var i = 0;
// Number of lines that have been split so far. i < listItems.length;
// length updated by breakAfter calls. ++i){
walk(listItems[i]);
}
// Make sure numeric indices show correctly. if (opt_startLineNum === (opt_startLineNum|0)){
listItems[0].setAttribute('value',opt_startLineNum);
}
var ol = document.createElement('OL');
ol.className = 'linenums';
var offset = Math.max(0,((opt_startLineNum - 1 /* zero index */
)) | 0) || 0;
for (var i = 0,n = listItems.length;
i < n;
++i){
li = listItems[i];
// Stick a class on the LIs so that stylesheets can // color odd/even rows,or any other row pattern that // is co-prime with 10. li.className = 'L' + ((i + offset) % 10);
if (!li.firstChild){
li.appendChild(document.createTextNode('\xA0'));
}
ol.appendChild(li);
}
node.appendChild(ol);
}
/** * Breaks{
@code job.sourceCode}
around style boundaries in *{
@code job.decorations}
and modifies{
@code job.sourceNode}
in place. * @param{
Object}
job like <pre>{
* sourceCode:{
string}
source as plain text,* spans:{
Array.<number|Node>}
alternating span start indices into source * and the text node or element (e.g.{
@code <BR>}
) corresponding to that * span. * decorations:{
Array.<number|string}
an array of style classes preceded * by the position at which they start in job.sourceCode in order *}
</pre> * @private */
function recombineTagsAndDecorations(job){
var isIE = /\bMSIE\b/.test(navigator.userAgent);
var newlineRe = /\n/g;
var source = job.sourceCode;
var sourceLength = source.length;
// Index into source after the last code-unit recombined. var sourceIndex = 0;
var spans = job.spans;
var nSpans = spans.length;
// Index into spans after the last span which ends at or before sourceIndex. var spanIndex = 0;
var decorations = job.decorations;
var nDecorations = decorations.length;
// Index into decorations after the last decoration which ends at or before // sourceIndex. var decorationIndex = 0;
// Remove all zero-length decorations. decorations[nDecorations] = sourceLength;
var decPos,i;
for (i = decPos = 0;
i < nDecorations;
){
if (decorations[i] !== decorations[i + 2]){
decorations[decPos++] = decorations[i++];
decorations[decPos++] = decorations[i++];
}
else{
i += 2;
}
}
nDecorations = decPos;
// Simplify decorations. for (i = decPos = 0;
i < nDecorations;
){
var startPos = decorations[i];
// Conflate all adjacent decorations that use the same style. var startDec = decorations[i + 1];
var end = i + 2;
while (end + 2 <= nDecorations && decorations[end + 1] === startDec){
end += 2;
}
decorations[decPos++] = startPos;
decorations[decPos++] = startDec;
i = end;
}
nDecorations = decorations.length = decPos;
var decoration = null;
while (spanIndex < nSpans){
var spanStart = spans[spanIndex];
var spanEnd = spans[spanIndex + 2] || sourceLength;
var decStart = decorations[decorationIndex];
var decEnd = decorations[decorationIndex + 2] || sourceLength;
var end = Math.min(spanEnd,decEnd);
var textNode = spans[spanIndex + 1];
var styledText;
if (textNode.nodeType !== 1 // Don't muck with <BR>s or <LI>s // Don't introduce spans around empty text nodes. && (styledText = source.substring(sourceIndex,end))){
// This may seem bizarre,and it is. Emitting LF on IE causes the // code to display with spaces instead of line breaks. // Emitting Windows standard issue linebreaks (CRLF) causes a blank // space to appear at the beginning of every line but the first. // Emitting an old Mac OS 9 line separator makes everything spiffy. if (isIE){
styledText = styledText.replace(newlineRe,'\r');
}
textNode.nodeValue = styledText;
var document = textNode.ownerDocument;
var span = document.createElement('SPAN');
span.className = decorations[decorationIndex + 1];
var parentNode = textNode.parentNode;
parentNode.replaceChild(span,textNode);
span.appendChild(textNode);
if (sourceIndex < spanEnd){
// Split off a text node. spans[spanIndex + 1] = textNode // TODO:Possibly optimize by using '' if there's no flicker. = document.createTextNode(source.substring(end,spanEnd));
parentNode.insertBefore(textNode,span.nextSibling);
}
}
sourceIndex = end;
if (sourceIndex >= spanEnd){
spanIndex += 2;
}
if (sourceIndex >= decEnd){
decorationIndex += 2;
}
}
}
/** Maps language-specific file extensions to handlers. */
var langHandlerRegistry ={
}
;
/** Register a language handler for the given file extensions. * @param{
function (Object)}
handler a function from source code to a list * of decorations. Takes a single argument job which describes the * state of the computation. The single parameter has the form *{
@code{
* sourceCode:{
string}
as plain text. * decorations:{
Array.<number|string>}
an array of style classes * preceded by the position at which they start in * job.sourceCode in order. * The language handler should assigned this field. * basePos:{
int}
the position of source in the larger source chunk. * All positions in the output decorations array are relative * to the larger source chunk. *}
}
* @param{
Array.<string>}
fileExtensions */
function registerLangHandler(handler,fileExtensions){
for (var i = fileExtensions.length;
--i >= 0;
){
var ext = fileExtensions[i];
if (!langHandlerRegistry.hasOwnProperty(ext)){
langHandlerRegistry[ext] = handler;
}
else if (window['console']){
console['warn']('cannot override language handler %s',ext);
}
}
}
function langHandlerForExtension(extension,source){
if (!(extension && langHandlerRegistry.hasOwnProperty(extension))){
// Treat it as markup if the first non whitespace character is a < and // the last non-whitespace character is a >. extension = /^\s*</.test(source) ? 'default-markup':'default-code';
}
return langHandlerRegistry[extension];
}
registerLangHandler(decorateSource,['default-code']);
registerLangHandler( createSimpleLexer( [],[ [PR_PLAIN,/^[^<?]+/],[PR_DECLARATION,/^<!\w[^>]*(?:>|$)/],[PR_COMMENT,/^<\!--[\s\S]*?(?:-\->|$)/],// Unescaped content in an unknown language ['lang-',/^<\?([\s\S]+?)(?:\?>|$)/],['lang-',/^<%([\s\S]+?)(?:%>|$)/],[PR_PUNCTUATION,/^(?:<[%?]|[%?]>)/],['lang-',/^<xmp\b[^>]*>([\s\S]+?)<\/xmp\b[^>]*>/i],// Unescaped content in javascript. (Or possibly vbscript). ['lang-js',/^<script\b[^>]*>([\s\S]*?)(<\/script\b[^>]*>)/i],// Contains unescaped stylesheet content ['lang-css',/^<style\b[^>]*>([\s\S]*?)(<\/style\b[^>]*>)/i],['lang-in.tag',/^(<\/?[a-z][^<>]*>)/i] ]),['default-markup','htm','html','mxml','xhtml','xml','xsl']);
registerLangHandler( createSimpleLexer( [ [PR_PLAIN,/^[\s]+/,null,' \t\r\n'],[PR_ATTRIB_VALUE,/^(?:\"[^\"]*\"?|\'[^\']*\'?)/,null,'\"\''] ],[ [PR_TAG,/^^<\/?[a-z](?:[\w.:-]*\w)?|\/?>$/i],[PR_ATTRIB_NAME,/^(?!style[\s=]|on)[a-z](?:[\w:-]*\w)?/i],['lang-uq.val',/^=\s*([^>\'\"\s]*(?:[^>\'\"\s\/]|\/(?=\s)))/],[PR_PUNCTUATION,/^[=<>\/]+/],['lang-js',/^on\w+\s*=\s*\"([^\"]+)\"/i],['lang-js',/^on\w+\s*=\s*\'([^\']+)\'/i],['lang-js',/^on\w+\s*=\s*([^\"\'>\s]+)/i],['lang-css',/^style\s*=\s*\"([^\"]+)\"/i],['lang-css',/^style\s*=\s*\'([^\']+)\'/i],['lang-css',/^style\s*=\s*([^\"\'>\s]+)/i] ]),['in.tag']);
registerLangHandler( createSimpleLexer([],[[PR_ATTRIB_VALUE,/^[\s\S]+/]]),['uq.val']);
registerLangHandler(sourceDecorator({
'keywords':CPP_KEYWORDS,'hashComments':true,'cStyleComments':true,'types':C_TYPES}
),['c','cc','cpp','cxx','cyc','m']);
registerLangHandler(sourceDecorator({
'keywords':'null,true,false'}
),['json']);
registerLangHandler(sourceDecorator({
'keywords':CSHARP_KEYWORDS,'hashComments':true,'cStyleComments':true,'verbatimStrings':true,'types':C_TYPES}
),['cs']);
registerLangHandler(sourceDecorator({
'keywords':JAVA_KEYWORDS,'cStyleComments':true}
),['java']);
registerLangHandler(sourceDecorator({
'keywords':SH_KEYWORDS,'hashComments':true,'multiLineStrings':true}
),['bsh','csh','sh']);
registerLangHandler(sourceDecorator({
'keywords':PYTHON_KEYWORDS,'hashComments':true,'multiLineStrings':true,'tripleQuotedStrings':true}
),['cv','py']);
registerLangHandler(sourceDecorator({
'keywords':PERL_KEYWORDS,'hashComments':true,'multiLineStrings':true,'regexLiterals':true}
),['perl','pl','pm']);
registerLangHandler(sourceDecorator({
'keywords':RUBY_KEYWORDS,'hashComments':true,'multiLineStrings':true,'regexLiterals':true}
),['rb']);
registerLangHandler(sourceDecorator({
'keywords':JSCRIPT_KEYWORDS,'cStyleComments':true,'regexLiterals':true}
),['js']);
registerLangHandler(sourceDecorator({
'keywords':COFFEE_KEYWORDS,'hashComments':3,// ### style block comments 'cStyleComments':true,'multilineStrings':true,'tripleQuotedStrings':true,'regexLiterals':true}
),['coffee']);
registerLangHandler(createSimpleLexer([],[[PR_STRING,/^[\s\S]+/]]),['regex']);
function applyDecorator(job){
var opt_langExtension = job.langExtension;
try{
// Extract tags,and convert the source code to plain text. var sourceAndSpans = extractSourceSpans(job.sourceNode);
/** Plain text. @type{
string}
*/
var source = sourceAndSpans.sourceCode;
job.sourceCode = source;
job.spans = sourceAndSpans.spans;
job.basePos = 0;
// Apply the appropriate language handler langHandlerForExtension(opt_langExtension,source)(job);
// Integrate the decorations and tags back into the source code,// modifying the sourceNode in place. recombineTagsAndDecorations(job);
}
catch (e){
if ('console' in window){
console['log'](e && e['stack'] ? e['stack']:e);
}
}
}
/** * @param sourceCodeHtml{
string}
The HTML to pretty print. * @param opt_langExtension{
string}
The language name to use. * Typically,a filename extension like 'cpp' or 'java'. * @param opt_numberLines{
number|boolean}
True to number lines,* or the 1-indexed number of the first line in sourceCodeHtml. */
function prettyPrintOne(sourceCodeHtml,opt_langExtension,opt_numberLines){
var container = document.createElement('PRE');
// This could cause images to load and onload listeners to fire. // E.g. <img onerror="alert(1337)" src="nosuchimage.png">. // We assume that the inner HTML is from a trusted source. container.innerHTML = sourceCodeHtml;
if (opt_numberLines){
numberLines(container,opt_numberLines);
}
var job ={
langExtension:opt_langExtension,numberLines:opt_numberLines,sourceNode:container}
;
applyDecorator(job);
return container.innerHTML;
}
function prettyPrint(opt_whenDone){
function byTagName(tn){
return document.getElementsByTagName(tn);
}
// fetch a list of nodes to rewrite var codeSegments = [byTagName('pre'),byTagName('code'),byTagName('xmp')];
var elements = [];
for (var i = 0;
i < codeSegments.length;
++i){
for (var j = 0,n = codeSegments[i].length;
j < n;
++j){
elements.push(codeSegments[i][j]);
}
}
codeSegments = null;
var clock = Date;
if (!clock['now']){
clock ={
'now':function (){
return +(new Date);
}
}
;
}
// The loop is broken into a series of continuations to make sure that we // don't make the browser unresponsive when rewriting a large page. var k = 0;
var prettyPrintingJob;
var langExtensionRe = /\blang(?:uage)?-([\w.]+)(?!\S)/;
var prettyPrintRe = /\bprettyprint\b/;
function doWork(){
var endTime = (window['PR_SHOULD_USE_CONTINUATION'] ? clock['now']() + 250 /* ms */
:Infinity);
for (;
k < elements.length && clock['now']() < endTime;
k++){
var cs = elements[k];
var className = cs.className;
if (className.indexOf('prettyprint') >= 0){
// If the classes includes a language extensions,use it. // Language extensions can be specified like // <pre class="prettyprint lang-cpp"> // the language extension "cpp" is used to find a language handler as // passed to PR.registerLangHandler. // HTML5 recommends that a language be specified using "language-" // as the prefix instead. Google Code Prettify supports both. // http://dev.w3.org/html5/spec-author-view/the-code-element.html var langExtension = className.match(langExtensionRe);
// Support <pre class="prettyprint"><code class="language-c"> var wrapper;
if (!langExtension && (wrapper = childContentWrapper(cs)) && "CODE" === wrapper.tagName){
langExtension = wrapper.className.match(langExtensionRe);
}
if (langExtension){
langExtension = langExtension[1];
}
// make sure this is not nested in an already prettified element var nested = false;
for (var p = cs.parentNode;
p;
p = p.parentNode){
if ((p.tagName === 'pre' || p.tagName === 'code' || p.tagName === 'xmp') && p.className && p.className.indexOf('prettyprint') >= 0){
nested = true;
break;
}
}
if (!nested){
// Look for a class like linenums or linenums:<n> where <n> is the // 1-indexed number of the first line. var lineNums = cs.className.match(/\blinenums\b(?::(\d+))?/);
lineNums = lineNums ? lineNums[1] && lineNums[1].length ? +lineNums[1]:true:false;
if (lineNums){
numberLines(cs,lineNums);
}
// do the pretty printing prettyPrintingJob ={
langExtension:langExtension,sourceNode:cs,numberLines:lineNums}
;
applyDecorator(prettyPrintingJob);
}
}
}
if (k < elements.length){
// finish up in a continuation setTimeout(doWork,250);
}
else if (opt_whenDone){
opt_whenDone();
}
}
doWork();
}
/** * Find all the{
@code <pre>}
and{
@code <code>}
tags in the DOM with *{
@code class=prettyprint}
and prettify them. * * @param{
Function?}
opt_whenDone if specified,called when the last entry * has been finished. */
window['prettyPrintOne'] = prettyPrintOne;
/** * Pretty print a chunk of code. * * @param{
string}
sourceCodeHtml code as html * @return{
string}
code as html,but prettier */
window['prettyPrint'] = prettyPrint;
/** * Contains functions for creating and registering new language handlers. * @type{
Object}
*/
window['PR'] ={
'createSimpleLexer':createSimpleLexer,'registerLangHandler':registerLangHandler,'sourceDecorator':sourceDecorator,'PR_ATTRIB_NAME':PR_ATTRIB_NAME,'PR_ATTRIB_VALUE':PR_ATTRIB_VALUE,'PR_COMMENT':PR_COMMENT,'PR_DECLARATION':PR_DECLARATION,'PR_KEYWORD':PR_KEYWORD,'PR_LITERAL':PR_LITERAL,'PR_NOCODE':PR_NOCODE,'PR_PLAIN':PR_PLAIN,'PR_PUNCTUATION':PR_PUNCTUATION,'PR_SOURCE':PR_SOURCE,'PR_STRING':PR_STRING,'PR_TAG':PR_TAG,'PR_TYPE':PR_TYPE}
;
}
)();
CSS代码(sunburst.css):
/* Pretty printing styles. Used with prettify.js. */
/* Vim sunburst theme by David Leibovic */
pre .str,code .str{color:#65B042;}
/* string - green */
pre .kwd,code .kwd{color:#E28964;}
/* keyword - dark pink */
pre .com,code .com{color:#AEAEAE;font-style:italic;}
/* comment - gray */
pre .typ,code .typ{color:#89bdff;}
/* type - light blue */
pre .lit,code .lit{color:#3387CC;}
/* literal - blue */
pre .pun,code .pun{color:#fff;}
/* punctuation - white */
pre .pln,code .pln{color:#fff;}
/* plaintext - white */
pre .tag,code .tag{color:#89bdff;}
/* html/xml tag - light blue */
pre .atn,code .atn{color:#bdb76b;}
/* html/xml attribute name - khaki */
pre .atv,code .atv{color:#65B042;}
/* html/xml attribute value - green */
pre .dec,code .dec{color:#3387CC;}
/* decimal - blue */
pre.prettyprint,code.prettyprint{background-color:#444;border-radius:4px;font-size:12px;line-height:18px;}
pre.prettyprint{width:95%;margin:0.3em auto 1em auto;padding:1em;white-space:pre-wrap;}
/* Specify class=linenums on a pre to get line numbering */
ol.linenums{margin-top:0;margin-bottom:0;color:#AEAEAE;}
/* IE indents via margin-left */
li.L0,li.L1,li.L2,li.L3,li.L5,li.L6,li.L7,li.L8{list-style-type:none}
/* Alternate shading for lines */
li.L1,li.L3,li.L5,li.L7,li.L9{}
@media print{pre .str,code .str{color:#060;}
pre .kwd,code .kwd{color:#006;font-weight:bold;}
pre .com,code .com{color:#600;font-style:italic;}
pre .typ,code .typ{color:#404;font-weight:bold;}
pre .lit,code .lit{color:#044;}
pre .pun,code .pun{color:#440;}
pre .pln,code .pln{color:#000;}
pre .tag,code .tag{color:#006;font-weight:bold;}
pre .atn,code .atn{color:#404;}
pre .atv,code .atv{color:#060;}
}




