一、字符编码的基本概念
字符编码(Character Encoding)指的是将字符映射到二进制数据的过程。计算机本身只能处理二进制数据,因此需要将人类可读的字符转换为计算机可读的数字。
在.NET C#编程中,常见的字符编码方式有ASCII、UTF-8、UTF-16等。相比较而言,UTF-8能够支持更多的字符,并且对于汉字等复杂文字能够提供更好的兼容性。因此,在本文中,将以UTF-8作为默认的字符编码方式进行讲述。
二、汉字个数获取的基本原理
在.NET C#编程中,要获取汉字个数,需要先将待统计的字符串转换为字符数组(char[]),然后通过遍历每一个字符,判断其是否为汉字来进行计算。
具体而言,判断字符是否为汉字,需要根据UTF-8编码方案中的编码规则来进行解析,即:
当一个字节的最高两位为“10”时,该字节不是汉字的首字节;
当一段连续的字节的最高两位均为“11”时,该段字节表示一个汉字。
根据上述规则,可以编写如下的代码实现汉字个数的获取:
public static int GetChineseCharCount(string str)
{
char[] charArr = str.ToCharArray();
int totalCount = 0;
for (int i = 0; i < charArr.Length; i++)
{
if ((charArr[i] & 0xff80) != 0 && (charArr[i] & 0xff00) != 0)
{
totalCount++;
}
}
return totalCount;
}三、.NET C#代码实现过程
1.新建一个控制台应用程序;
2.在Program.cs文件中,添加如下代码:
static Main(string[] args)
{
string testStr = "这是一个测试字符串!Hello, world!";
int chineseCharCount = GetChineseCharCount(testStr);
Console.WriteLine($"待统计字符串:{testStr}\n汉字个数为:{chineseCharCount}");
Console.ReadKey();
}
public static int GetChineseCharCount(string str)
{
char[] charArr = str.ToCharArray();
int totalCount = 0;
for (int i = 0; i < charArr.Length; i++)
{
if ((charArr[i] & 0xff80) != 0 && (charArr[i] & 0xff00) != 0)
{
totalCount++;
}
}
return totalCount;
}
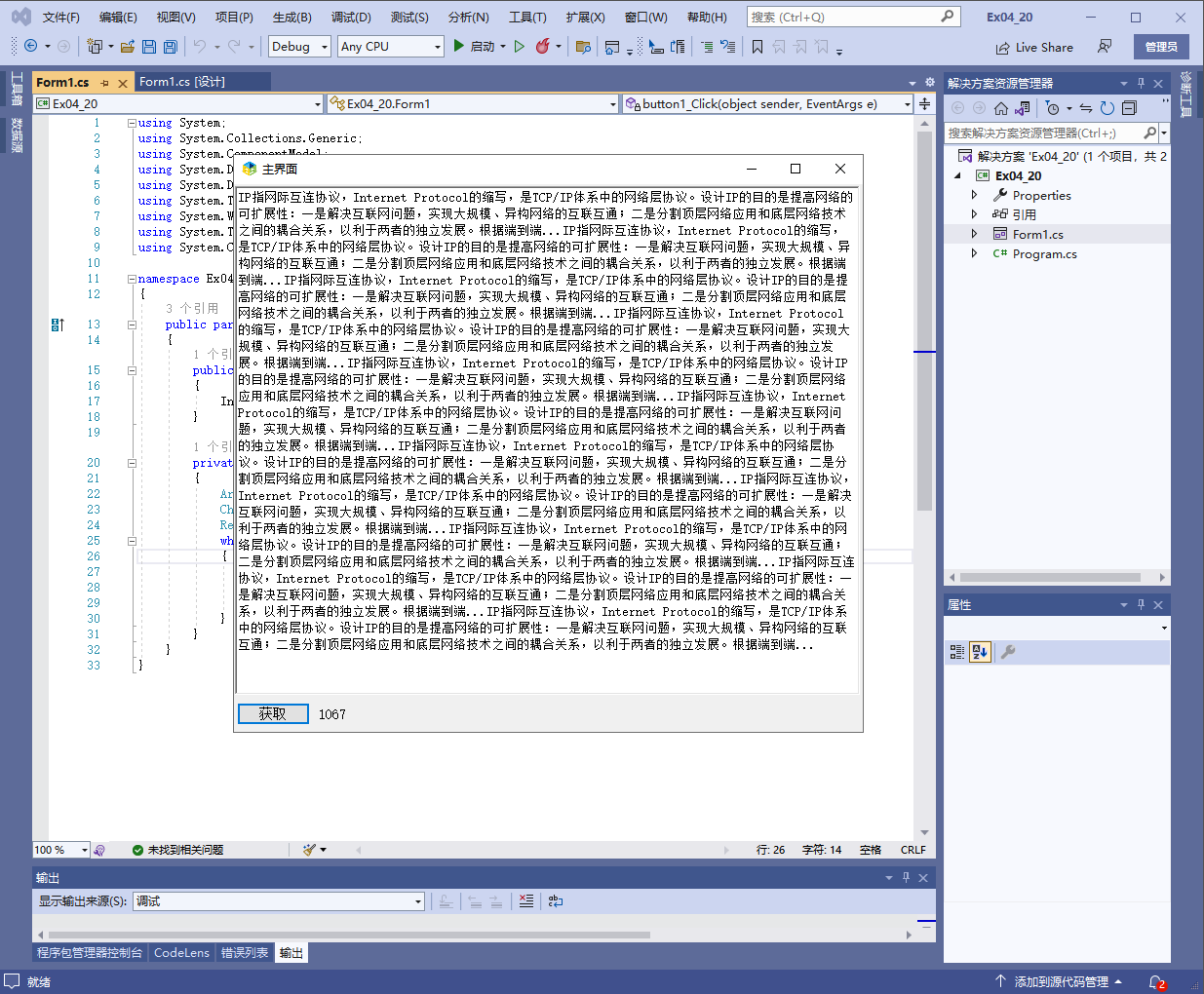
3.运行程序,查看结果。
也可以直接通过正则的方式获取:
public int CharCount(string txt)
{
ArrayList itemList = new ArrayList();
CharEnumerator CEnumerator = txt.GetEnumerator();
Regex regex = new Regex("^[\u4E00-\u9FA5]{0,}$");
while (CEnumerator.MoveNext())
{
if (regex.IsMatch(CEnumerator.Current.ToString(), 0))
itemList.Add(CEnumerator.Current.ToString());
}
return itemList.Count;
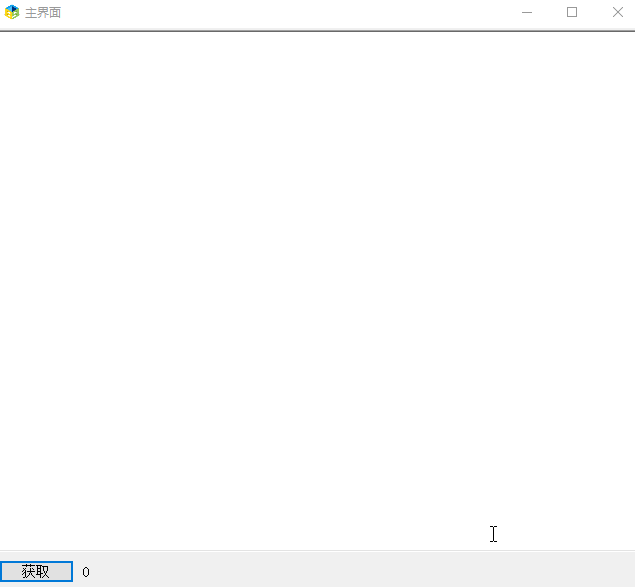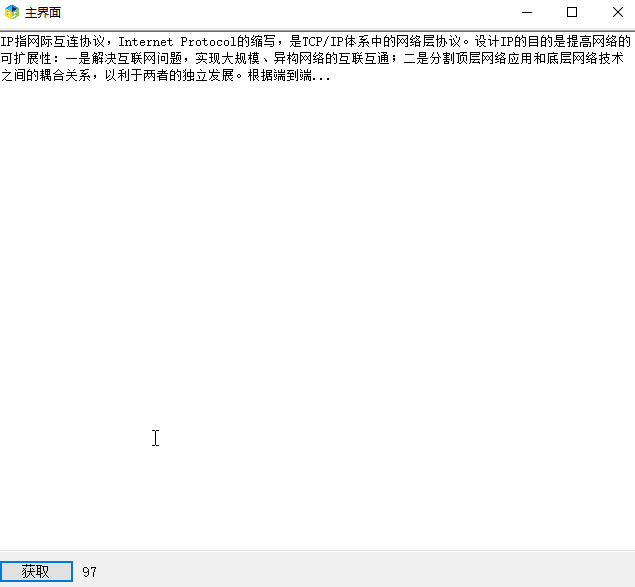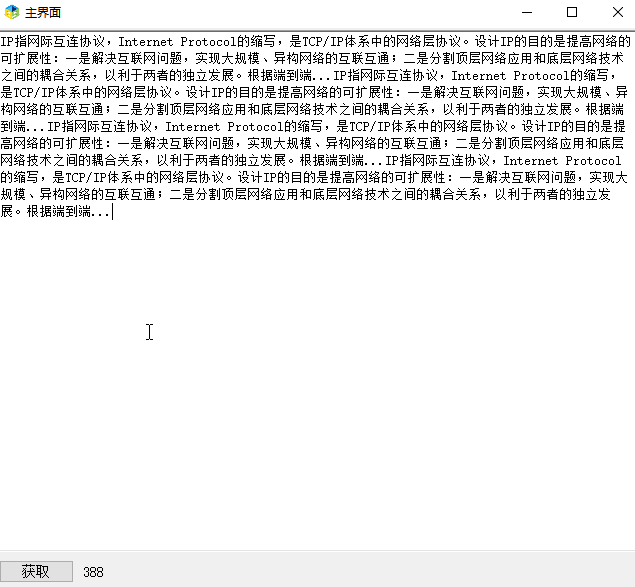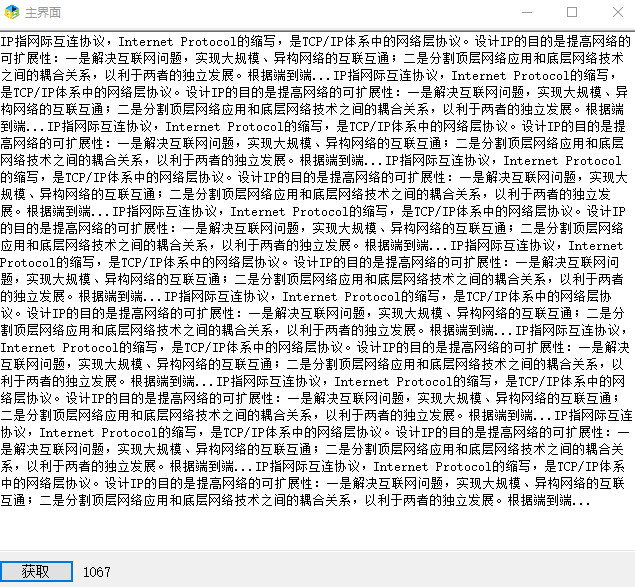
}效果如下: